

Articles les plus récents
Répondez à toutes vos questions grâce aux articles et témoignages proposés par les experts de Voxco et ses partenaires du secteur.



Five Takeaways from a Research Tech CEO on AI, Rigor, and Research (2026)
In a recent episode of the Insight Platforms Founders & Leaders podcast, Daniel Graff-Radford, CEO of Discuss, shared his perspective on where research technology is headed. The conversation ranged from AI hype cycles to blending qualitative and quantitative methodologies, but the through line was clear: the industry is in transition, and not all of the assumptions we’ve operated under still hold.
AI is accelerating expectations. Research cycles are compressing. Buyers are demanding both speed and depth. But according to Daniel, the real shift isn’t about replacing researchers or reinventing everything overnight. It’s about integrating AI in a way that strengthens methodology rather than shortcuts it.
Here are five key takeaways from the conversation.
Takeaway 1: AI Will Be the Default, But Not the Replacement
There is little debate that AI will become embedded in research workflows.
As Daniel put it: “AI-assisted research is going to be the default… it won’t change the need to have trust, rigor, and human voices at the center of those decisions.”
AI is becoming infrastructure. It will accelerate analysis, surface connections across datasets, and support continuous insight generation.
What it will not do is replace the researcher.
The more extreme vision — fully autonomous research cycles driven by synthetic respondents and AI-only interpretation — is something Daniel rejects outright:
“The idea that you’ll have AI synthetic data talking to AI researchers providing true insights is actually not a real thing. I think that is a silly dystopian future.”
Research exists because human opinions shift, markets evolve, and context changes. Capturing and interpreting that movement requires judgment. AI can assist, but it cannot substitute for that responsibility.
Takeaway 2: The Trade-Off Between Rigor and Speed Is Outdated
For years, research teams have operated under an implicit belief: if you want rigor, you accept slower timelines. If you want speed, you compromise depth.
Daniel challenges that assumption directly:
“We’ve always had this belief that’s no longer true, that rigor and speed are opposites.”
Historically, slower processes were equated with higher quality. More time meant more review, more validation, more methodological discipline.
But in today’s environment, equating slowness with rigor is increasingly impractical.
AI changes the dynamic, not by weakening methodology, but by enabling it to operate more efficiently. When embedded thoughtfully, AI reduces manual friction and accelerates synthesis without bypassing important steps.
However, Daniel also cautions against pursuing speed for its own sake:
“There is a desire to try to go too quickly and then you miss the insights for the slickness of the AI.”
The goal is not slick automation. It is a disciplined methodology operating at modern speed.
Takeaway 3: The Future of Research Is Blended, Not Siloed
Another theme from the conversation was the growing demand to combine scale and depth: quantitative measurement with qualitative understanding.
Researchers running large-scale quantitative studies increasingly want to know why certain patterns emerge. At the same time, those conducting in-depth qualitative interviews often want broader validation and scale.
As Daniel described, there is a real opportunity in “mixing the modes of qual and quant” to help customers reach differentiated decisions. The traditional siloed model — separate tools, separate teams, separate outputs — creates friction. Blending methodologies creates continuity.
AI plays a supporting role here as well. By accelerating cross-method synthesis and connecting insights across studies, it makes this blended approach more practical.
Takeaway 4: AI Is a Thought Partner, Not a Shortcut
If AI is not replacing researchers, and if rigor and speed can coexist, the next question becomes: what is AI actually doing inside research workflows?
Daniel’s answer is precise:
“AI as a thought partner in research.”
This positions AI not as a replacement for thinking, but as a collaborator in it.The quality of insight has always depended on the quality of the questions being asked. That dynamic does not disappear in an AI-enabled world.
“The quality of questions that a market researcher asks are so much better than someone that’s not trained in research.”
Experienced researchers know how to frame trade-offs, isolate variables, and interpret nuance. AI can assist by surfacing patterns, connecting prior studies, and accelerating synthesis, but it does not inherently understand context.
As Daniel puts it:
“AI is more of a tool in the hands of that market researcher… a thought partner… rather than something that overcomes needing them.”
The implication is clear: the strongest outcomes will come from skilled researchers working alongside AI, not from automation operating independently.
Takeaway 5: The Future Must Be Built Step by Step
While much of the AI conversation centers on bold future-state visions, Daniel takes a more grounded view. It’s easy to describe a world where researchers can instantly converse with a unified dataset containing every study ever conducted. But that is not the current reality.
“We’re not quite there yet… it’s our job to help light the path to get there.”
Transformation cannot be achieved in a leap. Research organizations operate within established workflows, stakeholder structures, and historical systems. Tools must be digestible. Change must be practical.
Daniel also warns that startups often make the mistake of pitching a three-year vision without solving today’s problems. Sustainable innovation requires grounding, not just ambition.
The future of research will be built incrementally, with each step strengthening methodology rather than discarding it.
Conclusion: Amplification, Not Automation
Across the conversation, one theme remains consistent: AI is reshaping research, but not by eliminating its foundations.
It will be embedded in workflows. It will accelerate synthesis. It will enable teams to operate with greater agility.
But it will not replace rigor.
It will not replace human judgment.
And it will not replace the trained researcher.
The next era of research is not autonomous. It is amplified.
Researchers who embrace AI as a thought partner, who blend qualitative depth with quantitative scale, and who move at modern speed without sacrificing discipline, will define what comes next.
And in 2026, that balance may matter more than ever.
Thank you for being a loyal follower of Voxco and Ascribe news. Please begin following Discuss on Linkedin to stay in the loop on new features, AI innovation, and customer success.
Read more

Les dernières tendances en études de marché
Construire l’avenir des études ensemble
Aujourd’hui marque le début d’un nouveau chapitre passionnant pour notre secteur et pour les équipes de Discuss, Voxco et Ascribe.
En nous unissant, nous créons quelque chose que, selon moi, le monde des études attendait depuis longtemps : un écosystème connecté qui unit la profondeur du qualitatif, la portée du quantitatif et l’intelligence de l’IA au sein d’un même flux. C’est la prochaine étape dans la manière dont nous comprenons les gens et prenons des décisions avec confiance.
Unir ces équipes ressemble moins à une fusion qu’à un puzzle qui s’assemble, chaque pièce trouvant naturellement sa place pour créer une vision plus complète de ce que les études devraient être.
Discuss apporte l’art et l’empathie du qualitatif – la capacité à comprendre ce que les gens ressentent et pourquoi – et les associe à une innovation en IA de classe mondiale, rendant cette compréhension plus rapide, plus riche et plus échelonnable que jamais.
Voxco y ajoute la rigueur scientifique, la portée et la crédibilité de décennies d’expertise quantitative, avec la précision qui garantit des insights à la fois solides et représentatifs.
Et Ascribe apporte la puissance de l’analyse textuelle par l’IA, servant de lien entre le langage et la structure, puis entre la structure et la clarté.
Pourquoi avoir choisi la marque Discuss
Nous avons choisi le nom Discuss car il incarne ce qui nous tient profondément à cœur : une compréhension humaine authentique. La marque Discuss représente déjà la qualité, l’innovation et l’empathie. Elle capture l’essence même de ce que doivent être les études: un dialogue, au-delà d’un simple ensemble de données.
En tant qu’équipe issue du monde du quantitatif, nous savons à quel point la technologie peut rendre les études efficaces, mais impersonnelles. Ce que j’aime chez Discuss, c’est justement l’inverse : la plateforme place les personnes au centre, même lorsque l’IA accélère le travail autour d’elles. Cet équilibre entre vitesse et humanité est la base de notre avenir commun.
Une nouvelle opportunité
Lorsque nous avons réuni Voxco et Ascribe en 2024, nous avons entrevu ce qu’il est possible d’accomplir quand la rigueur du quantitatif rencontre la nuance du qualitatif. Avec l’arrivée de Discuss, cette vision s’est élargie pour devenir une véritable nouvelle dimension, où l’insight évolue à la vitesse de la curiosité.
Ensemble, nous créons un monde où la technologie éclaire le sens. Notre objectif est clair et porteur de sens : donner à chaque professionnel·le des études les superpouvoirs nécessaires pour transformer la curiosité en clarté.
Reconnaissance envers Simon Glass et l’équipe de Discuss
Je tiens à exprimer ma profonde gratitude à Simon Glass et à toute l’équipe de Discuss. Ils ont construit quelque chose de vraiment exceptionnel : une entreprise fondée sur l’élégance, l’empathie et une attention constante au client.
Je suis ravi que Simon continue à travailler étroitement avec moi et avec l’équipe de direction de Discuss en tant que conseiller. Dans mon nouveau rôle de PDG de Discuss, son soutien garantira que l’esprit et l’excellence qui définissent Discuss restent au cœur de tout ce que nous construirons ensemble.
La vision et le soutien de Terminus Capital Partners
Cette étape majeure n’aurait pas été possible sans la vision et le partenariat de Terminus Capital Partners (TCP). Leur conviction dans la puissance des technologies d’études intégrées et modernes nous a permis d’évaluer des dizaines d’opportunités et de concrétiser celles qui pouvaient réellement transformer le secteur.
Discuss s’est démarquée non seulement par son innovation et son leadership en IA, mais aussi par son engagement envers la réussite du client et son approche profondément humaine de la technologie.
La puissance de l’IA : donner des superpouvoirs aux professionnel·les des études
L’IA est à la base d’une nouvelle ère pour les études. Elle permet aux équipes de voir plus loin, de mieux connecter les points et de décider plus vite, sans perdre le contexte humain qui donne du sens aux données.
Ce qui m’enthousiasme le plus, c’est ce que l’IA rend désormais possible pour les professionnel·les des études : la combinaison de Discuss, Voxco et Ascribe leur offre pour la première fois la capacité d’obtenir des réponses fiables en passant aisément de la profondeur qualitative à l’échelle quantitative, de la conversation à la quantification, le tout au sein d’un même système pensé pour la clarté et la connexion.
Avec Discuss, nous apportons une plateforme propulsée par l’IA, capable d’allier vitesse et profondeur humaine. Nos agents IA pour l’interview, la synthèse des insights et la conception de projets permettent déjà aux équipes de mener des études globales au rythme de la prise de décision. Qu’elles soient menées par des humains, modérées par l’IA ou en mode hybride, Discuss transforme les insights qualitatifs en une source d’apprentissage continue.
Avec Voxco, nous ajoutons le moteur quantitatif : notre expertise historique en conception de sondages, en collecte de données et en automatisation donne aux professionnel·les des études la portée et la rigueur statistique nécessaires pour valider leurs observations.
Et avec Ascribe, nous intégrons des capacités avancées d’analyse textuelle par IA, notamment la codification automatique des réponses ouvertes, l’analyse de sentiment et l’intelligence inter-projets. Ces fonctionnalités transforment les mots en schémas, les schémas en prédictions et les prédictions en actions.
Imaginez maintenant ces capacités réunies au sein d’un seul système.
Un·e professionnel·le des études formule une question, et le système exécute ce qui nécessitait autrefois plusieurs outils et équipes. Le moteur de sondage Voxco trouve et interroge les bons publics sur plusieurs canaux et régions, capturant les signaux quantitatifs qui fondent chaque décision. Les agents IA de Discuss lancent ensuite des entretiens humains ou modérés par IA pour révéler les émotions et les récits derrière les chiffres. Enfin, les analyses d’Ascribe relient le tout, décodant les réponses ouvertes, cartographiant les sentiments et révélant les modèles qui relient ce que les gens disent à ce qu’ils font.
Dans un environnement unique, les équipes peuvent concevoir, collecter et connecter, passant sans transition de l’exploration à la validation, des données à la compréhension. Ce système ne se contente pas d’analyser les informations, il apprend d’elles, enrichissant chaque question et approfondissant chaque réponse.
Ce n’est que le début.
Cliquez ici pour lire le communiqué de presse complet.
Daniel Graff-Radford
PDG, Discuss
Read more

Analyse de texte & IA
Les dernières tendances en études de marché
Why CATI and Offline Surveys Still Matter in an AI-Dominated World
In a World Obsessed with Automation, Human Connection Still Counts
Have you ever tried to reach customer support, only to get stuck talking to a chatbot that can’t quite understand your problem? You rephrase your issue, try a few keywords, maybe even hit “Other” twice, and still end up with a scripted response that doesn’t help. You end the chat feeling unheard.
Situations like that remind us that technological progress means little if we lose human touch along the way.
The same tension exists in research. AI can process vast amounts of data, predict behavior, and summarize open-ends in seconds. But when the goal is to understand why people think or act a certain way, automation alone falls short. Human-centered research methods like computer assisted telephone interviewing software (CATI) and offline surveys bridge that gap. They invite conversation, clarify meaning, and uncover the emotion behind each response.
AI can amplify research in remarkable ways, but there will always be voices, contexts, and conversations that only CATI and offline methods can reach.
Beyond Automation: The Role of Human Intelligence in Research
When researchers rely solely on AI, they risk missing the subtle cues that define real understanding. Human-led methods like CATI and offline interviewing capture these cues, emotion, tone, hesitation, that give data depth and authenticity.
At Voxco, we call this the balance of AI + HI (Artificial Intelligence + Human Intelligence).
- AI can flag emotional tone, but only people can ask why someone feels that way.
- AI can record every word, but only people can read between them.
The future of research isn’t man versus machine. It’s about using both, AI for efficiency, humans for empathy.
CATI in the AI Era: Smarter Calls, Deeper Insights
CATI has always been about more than a script. It’s a live conversation that builds trust, clarifies meaning, and captures what online surveys often miss. Today, AI is transforming how those conversations happen.
Here’s what modern CATI looks like:
- AI-assisted dialers optimize call timing and reduce idle time.
- Real-time transcription tools capture every word accurately.
- Voice analytics detect emotional tone and engagement.
- AI-driven coding tools, like Ascribe, instantly summarize open-ended feedback.
What remains unchanged is the human role. Interviewers still adapt to the moment, sense when to probe deeper, and navigate complex emotions. AI handles the repetitive work so that researchers can focus on what truly matters: listening and interpreting.
Offline Surveys: The Unsung Hero of Data Completeness
Even in an age of hyperconnectivity, not everyone lives online. Many communities such as rural populations, older adults, or regions with limited infrastructure, are still best reached in person. Offline surveys keep these voices in the dataset.
Offline data collection plays a vital role in:
- Healthcare and social studies, where context, empathy, and trust matter.
- Field research in remote areas, where internet access is unstable.
- Post-disaster assessments, where quick, direct input guides real-time decisions.
With AI-enabled offline tools, researchers can now collect and sync data seamlessly. Mobile survey apps can:
- Encrypt and store data securely offline.
- Flag inconsistencies or outliers instantly.
- Sync findings automatically once a connection is restored.
Offline doesn’t mean outdated, it means inclusive. It ensures research reflects every voice, not just those with reliable Wi-Fi.In a world where representativeness defines credibility, offline surveys remind us that good research starts by showing up where people are.
Combining AI and Traditional Research Methods for the Future
The future of research isn’t about choosing between automation and authenticity. It’s about knowing how and when to use both.
AI and traditional survey methods now work hand in hand to create faster, fuller, and more reliable insights. CATI interviews feed AI-driven text analysis. Offline survey data syncs seamlessly into central dashboards. Machine learning tools spot anomalies long before they affect data quality.
Think of it as a feedback loop.
- CATI and offline methods capture context and emotion.
- AI tools extract patterns and scale those findings.
- Researchers interpret and validate what truly matters.
When every mode supports the others, the result is an insight process that is both human and high-tech. This is the real meaning of “AI with HI”, a research ecosystem that blends empathy with efficiency.
3 Ways to Future-Proof Human-Led Research
Even as automation expands, the most valuable insights will still come from people who know how to use technology without losing touch with the human side of research. Here are three ways researchers can keep CATI and offline methods future-ready in an AI-driven world:
1. Let AI handle the heavy lifting
Use AI to take care of the tasks that slow you down like scheduling, transcription, and quality checks. Modern CATI and offline tools can automatically log call data, summarize open-ends, and flag inconsistencies before they reach your dataset. When routine work runs in the background, researchers can focus on what truly matters: asking better questions and interpreting richer answers.
2. Reinvest in human touchpoints
Use CATI and offline surveys strategically, where tone, timing, or context could shape how someone responds. A well-timed call or in-person conversation can surface the “why” behind behaviors that AI alone can’t decode. It’s not about doing more human research. It’s about using human connection at the moments that matter most.
3. Build a hybrid mindset
The most effective researchers today see all modes — online, CATI, and offline — as part of one ecosystem. When these channels work together, you get a fuller picture of your audience and stronger, more balanced data. Treat AI as your co-pilot, not your replacement. It can accelerate discovery, but it still needs a human to guide the journey.
Conclusion: Innovation Rooted in Connection
CATI and offline surveys aren’t relics of the past. They’re the grounding force of modern research — keeping insights real, representative, and rooted in context. The future belongs to researchers who can blend the two worlds: human instinct and machine intelligence.
That’s where Voxco comes in. Our platform brings every mode together — online, CATI, and offline — in one ecosystem built to help you move faster without losing depth. See how leading research teams use Voxco to combine AI power with human precision. Book a demo now.
Read more

Les dernières tendances en études de marché
Pourquoi les professionnels des études, et non les algorithmes, doivent rester au centre de l’IA
Cet article a été initialement publié en anglais.
Trop souvent, l’IA reste une boîte noire. Dans de nombreuses organisations, l’IA appliquée aux études ressemble encore à une boîte noire : les données entrent, les résultats sortent, mais personne ne peut expliquer comment ces résultats ont été produits. J’ai constaté à quel point cela peut laisser les équipes d’études perplexes, voire méfiantes, face à la fiabilité des résultats. Pour être utile, l’IA doit produire des résultats reproductibles, transparents et fiables.
Notre philosophie d’une IA responsable
Chez Voxco, nous croyons que l’IA doit créer les conditions d’un meilleur jugement humain, sans jamais le remplacer. Sa véritable valeur se révèle lorsqu’elle travaille aux côtés de professionnel·les des études qualifié·es, capables d’apporter du contexte, de remettre en question les hypothèses et de décider de ce qui compte vraiment.
Michael Link, PhD, une figure majeure du secteur, rappelle que plus de 70 % des équipes utilisent désormais l’IA, mais moins de 10 % valident réellement les résultats. C’est précisément pourquoi l’IA responsable est essentielle. Notre philosophie est simple : l’IA doit élargir les capacités des professionnel·les des études sans leur retirer le contrôle. Avec les bonnes garanties, elle peut alléger les tâches répétitives tout en libérant du temps pour tester plus de marchés, analyser plus de données et explorer davantage de questions, sans augmenter les budgets.
L’histoire montre que les meilleures technologies n’effacent pas l’expertise ; elles la prolongent. Tout comme les logiciels de traitement de texte ont facilité l’écriture sans supprimer la réflexion, l’IA accélère l’analyse tout en s’appuyant sur la supervision humaine pour donner du sens. Les professionnel·les des études restent au centre du processus, garants de la rigueur et de la fiabilité des insights.
Trois principes pour une IA réellement utile
La conversation sur l’IA responsable devient souvent trop théorique. Voici trois règles concrètes qui, selon notre expérience, font la différence :
1. Utilisez l’IA pour la mise à l’échelle, pas pour le jugement
L’IA excelle dans le volume : elle peut approfondir automatiquement les réponses ouvertes (Approfondissement par l’IA), coder des milliers de verbatims en quelques heures ou identifier des thèmes émergents. Mais elle ne sait pas encore quels thèmes comptent le plus ni comment les interpréter. L’erreur la plus fréquente consiste à confondre prédiction et signification. La leçon à retenir : laissez l’IA supprimer les goulots d’étranglement, mais gardez le jugement humain au centre.
2. Validez tôt et souvent
Le danger de l’IA « boîte noire » est la fausse confiance. Si vous ne pouvez pas reproduire ou expliquer un résultat, vous ne pouvez pas vous y fier. Les équipes d’études doivent traiter les sorties d’IA comme n’importe quel jeu de données : les comparer, les tester et les confronter à la réalité. C’est ainsi qu’elles gagnent confiance dans la qualité des résultats.
3. Gardez l’humain dans la boucle, toujours
Les professionnel·les des études doivent pouvoir examiner, corriger et questionner les résultats à chaque étape. C’est ce qui empêche les biais de passer inaperçus ou les anomalies d’être ignorées. Chez Voxco, nous parlons souvent de la différence entre une IA assistante et une IA décisionnaire : la première élargit les possibilités, la seconde présente un risque que personne ne devrait prendre.
Des outils qui reflètent cette philosophie
Une IA responsable n’a de valeur que si elle s’applique concrètement. C’est pourquoi nous avons conçu des outils qui allègent le travail répétitif tout en maintenant les professionnel·les des études aux commandes.
- Ascribe Coder accélère l’analyse des réponses ouvertes. Les projets qui demandaient autrefois plusieurs jours de codification peuvent désormais être réalisés en une fraction du temps, avec des vérifications humaines garantissant la précision. Les utilisateurs constatent jusqu’à 90 % de réduction du temps d’analyse tout en élargissant leur portée.
- Ask Ascribe permet d’interroger directement ses propres données pour identifier les thèmes, émotions et synthèses, et obtenir des insights exploitables immédiatement.
- L’Approfondissement par l’IA de Voxco ajoute de la profondeur aux enquêtes en posant des questions de relance contextuelles en temps réel, permettant d’obtenir des réponses plus riches et plus exploitables.
- AI Survey Import transforme automatiquement un questionnaire Word en enquête structurée prête à être testée et personnalisée, tout en laissant le contrôle total à l’utilisateur.
Chez Voxco, nous faisons la différence entre l’IA grand public et l’IA conçue pour les études. Les outils grand public peuvent être rapides, mais ils ne répondent pas aux exigences de rigueur, de validation, de confidentialité et de reproductibilité qui définissent notre domaine. Nos solutions sont pensées par et pour les professionnel·les des études : elles s’intègrent à chaque étape du processus, respectent les standards du secteur et évoluent grâce aux retours de la communauté.
Un bon exemple : Toluna a constaté une économie de temps de près de 90 % sur la codification et l’analyse, tout en maintenant une précision constante sur de larges jeux de données multilingues avec AI Coder. En automatisant les regroupements, en soutenant la création de codebooks réutilisables et en laissant les professionnel·les des études valider les résultats, Toluna a renforcé la qualité et la fiabilité de ses analyses.
À retenir
L’IA peut accélérer les insights, mais sans supervision humaine, elle se transforme vite en bruit. Les organisations doivent poser des questions plus exigeantes à leurs partenaires :
- Pouvez-vous expliquer comment les résultats ont été produits ?
- Les outils laissent-ils les professionnel·les garder le contrôle ?
- Les résultats sont-ils transparents et défendables ?
Si la réponse est non, les risques dépassent les bénéfices. Lorsqu’elle renforce la rigueur au lieu de la remplacer, l’IA devient un véritable levier de confiance, au service de décisions fondées et défendables.
Read more

Les dernières tendances en études de marché
Analyse de texte & IA
Le génie du sous-sol ne peut plus nous sauver : du bricolage à un véritable partenariat avec l’IA
Cet article a été initialement publié en anglais.
Imaginez la scène : Il est deux heures du matin. Dans le sous-sol d’un institut d’études par sondage, un programmeur penché sur trois écrans fait face à une montagne de canettes de boissons énergétiques vides. Le client attend l’impossible pour le lendemain matin : une logique de quotas personnalisée qui ne devrait même pas exister, un format d’exportation de données illogique, et un flux d’enquête qui ferait pleurer un docteur en logique.
Et pourtant, Fariborz y parvient.
Vous connaissez sûrement un « Fariborz ». Peut-être que, chez vous, il s’appelle Suresh, Bill, Larry ou Nate. Chaque organisation d’études a son « gourou du sous-sol », ce programmeur brillant, un peu mystérieux, capable de faire chanter un système CATI comme un ténor et de transformer une plateforme web en cirque bien rodé. Véritables armes secrètes, ces experts transformaient un « absolument impossible » client en un « ce sera prêt lundi, avec documentation ».
Pendant des décennies, cette culture de l’ingéniosité maison a été notre avantage concurrentiel. Elle nous a permis de traverser tous les grands bouleversements du secteur : du papier à la collecte téléphonique assistée par ordinateur (CATI), du CATI aux approches multi-canal, puis à la révolution numérique. Et cela fonctionnait parfaitement, car ces transitions étaient prévisibles. Les mathématiques restaient stables, la logique était déterministe, et un seul programmeur talentueux pouvait faire tourner l’ensemble d’une opération pendant des années avec seulement quelques ajustements ponctuels.
Lorsque les clients demandaient des personnalisations, les besoins étaient clairs : des logiques de saut cohérentes, des exports familiers, des quotas rationnels. Le génie était juste au bout du couloir, les corrections étaient rapides, abordables et presque toujours précises. C’était comme posséder un couteau suisse capable de résoudre n’importe quel problème.
Puis l’IA est arrivée. Et soudain, ce modèle d’agilité, autrefois notre force, pourrait bien devenir notre plus grand risque.
Le jour où Fariborz a trouvé plus fort que lui
L’IA n’est pas une simple mise à jour logicielle ni un nouvel outil dans notre boîte habituelle. C’est une entité totalement différente, qui obéit à des règles radicalement nouvelles.
Contrairement aux systèmes déterministes auxquels nous étions habitués, l’IA, et plus particulièrement l’IA générative, est par nature non déterministe. Donnez-lui la même entrée le mardi que la veille, et vous pourriez obtenir une sortie différente. Non pas parce qu’il y a une erreur, mais parce que c’est ainsi qu’elle fonctionne. Conçue pour imiter la « pensée » humaine, elle reproduit aussi son imprévisibilité.

De plus, les systèmes d’IA exigent une attention constante que les logiciels traditionnels ne demandaient pas. Les modèles « dérivent » à mesure que le langage évolue, que les populations changent ou que de nouvelles versions sont publiées. Ce qui fonctionnait parfaitement pour la codification automatique des réponses ouvertes en janvier peut échouer subtilement en juin sans qu’on s’en rende compte, à moins d’une surveillance active.
Et le plus déroutant, c’est qu’une IA ne peut souvent pas expliquer ses propres décisions. Sans outils sophistiqués d’interprétabilité, vous ne saurez peut-être jamais pourquoi un modèle a classé une réponse d’une certaine manière plutôt qu’une autre. Comme je l’ai soutenu dans Beyond the Black Box, les systèmes d’IA doivent être transparents, auditables et explicables, non seulement pour des raisons éthiques, mais aussi pratiques.
Comme je l’ai également averti dans Le problème de la quatrième luciole, sans vigilance, nous risquons de perdre complètement la trace des voix minoritaires et des cas rares mais essentiels. Le plus inquiétant ? Nous pourrions ne jamais nous en rendre compte.
En résumé : on ne peut pas « configurer et oublier » un système d’IA comme un logiciel d’enquête traditionnel. Et cette fois, il n’y a plus de Fariborz en coulisse pour rattraper les erreurs. Ces systèmes exigent un suivi continu, une reformation régulière et une gouvernance active, sinon ils échoueront silencieusement, et vous ne le découvrirez que bien trop tard.
Pourquoi l’IA échoue en silence
J’ai vu ce qui se passe quand la gouvernance fait défaut, et cela devrait tenir éveillé tout directeur d’études.
Une organisation avait développé en interne un classificateur de texte pour coder les réponses ouvertes. Pendant plusieurs mois, il a parfaitement fonctionné : plus rapide que les codeurs humains, plus cohérent, moins coûteux. Les dirigeants étaient ravis.
Six mois plus tard, un audit de routine a révélé que le système avait progressivement cessé de classifier correctement les réponses en espagnol. Aucun signal d’alerte, aucun message dans le tableau de bord, rien. Plus de 400 répondants hispaniques avaient été mal classés, leurs voix déformées dans les données.
Cette défaillance silencieuse durait depuis des mois avant d’être détectée. C’est le danger sournois d’une IA sans gouvernance. Les systèmes ne s’effondrent pas de façon spectaculaire : ils s’éloignent doucement de la précision, emportant avec eux l’intégrité de vos données. La dérive des modèles dégrade les résultats sans prévenir. Les biais s’installent peu à peu, ignorant certains groupes minoritaires ou renforçant des stéréotypes. Et la charge en compétences est énorme : il faut des data scientists, des ingénieurs en apprentissage automatique, des spécialistes de la conformité, pas seulement quelques programmeurs ingénieux.
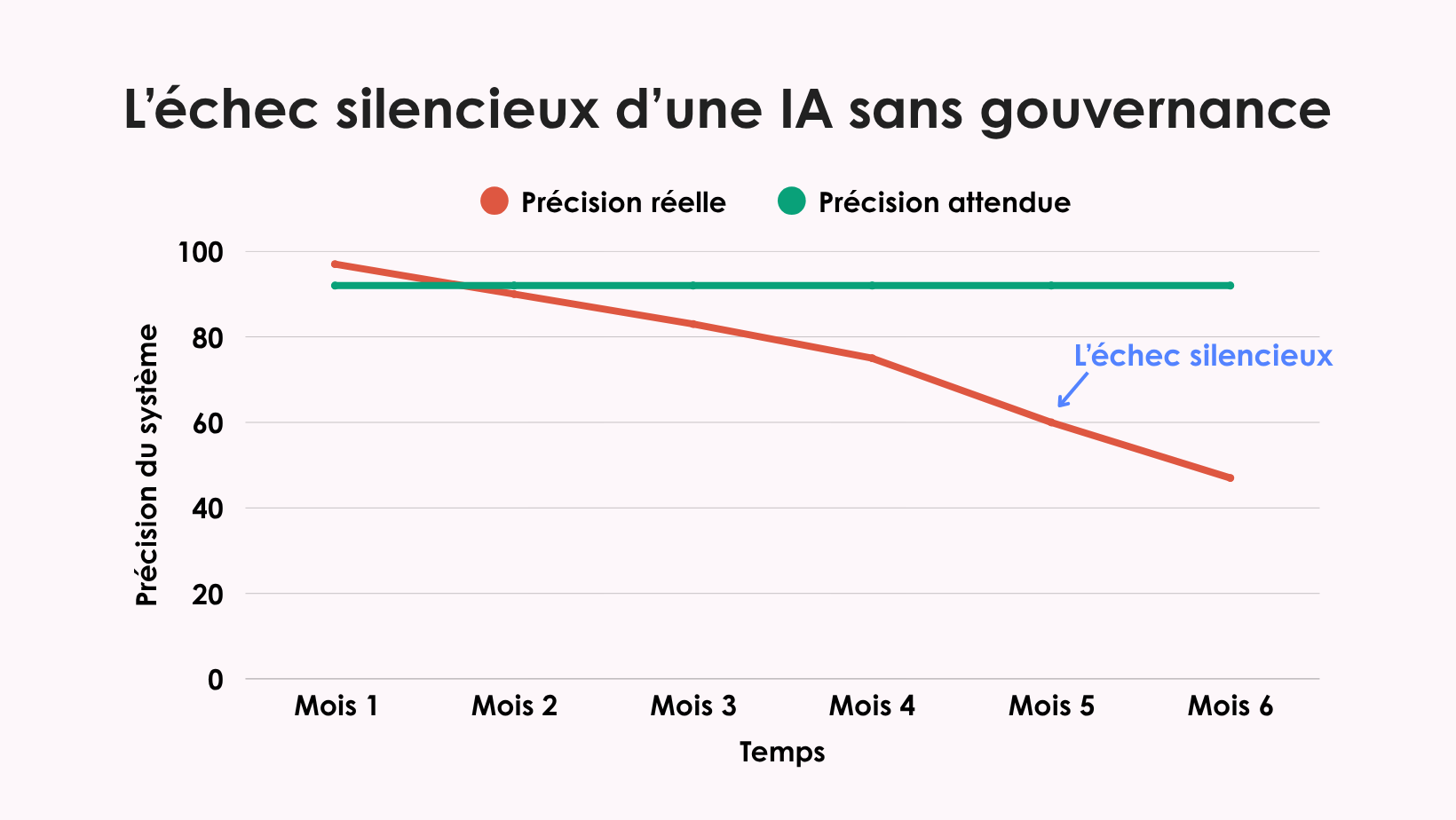
À cela s’ajoute l’exposition réglementaire. Le RGPD et la norme HIPAA exigent une documentation claire sur le fonctionnement des modèles et la protection des données. Le cadre du NIST est peut-être « volontaire », mais essayez d’expliquer cela à vos clients si votre système d’IA échoue à un audit. Votre génie du sous-sol peut-il assurer tout cela en plus de maintenir vos opérations ?
Le génie solitaire ne peut plus porter cette responsabilité. Lui demander de le faire n’est plus seulement irréaliste, c’est dangereux.
Quand le bricolage reste utile
Pas de panique : le bricolage n’est pas totalement mort. Il reste parfaitement adapté pour :
- Les projets pilotes et expérimentations en phase d’apprentissage
- Les outils internes répondant à des besoins très spécifiques
- Les prototypes destinés à évaluer l’intérêt d’un investissement plus important
Mais dès qu’un outil maison devient visible par le client, critique pour la conformité ou essentiel à la mission, tout change.
Pourquoi les partenariats stratégiques comptent
C’est pour cela que le travail en partenariat est devenu indispensable. Certaines entreprises consacrent entièrement leur activité au développement de plateformes d’enquête, ce qui signifie aujourd’hui : suivre le rythme effréné de l’IA.
Ces organisations disposent d’équipes spécialisées dans la surveillance des modèles, la mise en place de pipelines MLOps, la détection des dérives et biais, et le suivi des réglementations de confidentialité en constante évolution. Surtout, leur modèle économique repose sur la réussite continue de ces tâches.
En vous associant à des spécialistes de plateforme, votre équipe peut se concentrer sur ce qui la distingue vraiment : comprendre les répondants, servir les clients et faire progresser la science des études.
Une gouvernance pratique sans perdre la tête
Même en collaborant avec des spécialistes de l’IA, la gouvernance reste votre responsabilité. La bonne nouvelle ? Une gouvernance efficace ne requiert ni doctorat en apprentissage automatique, ni budget colossal.
Voici votre kit de départ pratique :
- Établir une référence de performance : fixez un taux de précision de base au lancement, puis vérifiez-le chaque trimestre pour garantir la cohérence. Aucune exception.
- Identifier les valeurs aberrantes : mettez en place un processus de révision humaine des résultats inhabituels. Ces cas limites révèlent souvent les problèmes avant qu’ils ne s’étendent.
- Auditer les biais : testez vos modèles sur différents sous-groupes démographiques. Si les résultats varient de manière injustifiée, vous le saurez tôt.
- Tout documenter : comment le modèle a été entraîné, quand il a été mis à jour, quels indicateurs vous suivez. Ce n’est plus facultatif, c’est obligatoire.
Le test des trois questions
Avant de créer un nouvel outil d’IA, passez ce test simple. Si vous ne pouvez pas répondre aux trois questions avec précision, arrêtez-vous.
- Qui est responsable du modèle après son lancement ?
Identifiez les personnes précises chargées du suivi, de la reformation et de la validation. « L’équipe » n’est pas une réponse. - Comment saurez-vous qu’il échoue ?
Les échecs de l’IA sont silencieux. Quelles alertes ou quels tableaux de bord détecteront les problèmes avant que vos clients ne s’en aperçoivent ? - Que se passe-t-il à l’échelle × 10 ?
Votre infrastructure, votre personnel et votre gouvernance peuvent-ils gérer dix fois plus de volume sans rupture ?
Si vous ne pouvez pas répondre à ces questions de façon concrète, c’est le signal qu’il faut renforcer votre gouvernance ou collaborer avec un partenaire capable de gérer cette complexité.
En conclusion
L’ère du génie du sous-sol ne reviendra pas, du moins pas avec l’IA. Nous devons construire des écosystèmes d’études où les experts humains et l’IA travaillent ensemble de manière sûre, transparente et à grande échelle.
Fariborz a été notre atout secret pendant des décennies. Mais aujourd’hui, qui surveille les modèles ? Êtes-vous certain qu’ils resteront précis dans six mois ?
Le plus grand risque n’est pas d’avancer trop lentement, mais d’avancer sans garde-fous, en déployant des systèmes qui fonctionnent parfaitement jusqu’à ce qu’ils échouent silencieusement, compromettant l’intégrité de vos données.
Les modèles ont besoin de leurs propres surveillants. Pouvez-vous vous permettre une gouvernance de l’IA rigoureuse ? Mieux vaut poser la vraie question : pouvez-vous vous permettre de ne pas en avoir ?
Read more

Analyse de texte & IA
Les dernières tendances en études de marché
Quand la quatrième luciole vit dans vos données : détecter les changements liés à l’IA avant qu’ils ne faussent vos résultats
Cet article a été initialement publié en anglais.
Ce qu’une simple illustration m’a appris sur la validation de l’IA
Il y a quelques mois, je générais des illustrations pour un livre pour enfants à l’aide d’une IA. La consigne était simple : trois lucioles brillant dans le ciel d’été. À chaque fois, l’IA m’en donnait quatre. Peu importe la manière dont je reformulais la requête, cette quatrième luciole non invitée apparaissait toujours.
Dans une image, cette luciole supplémentaire sautait aux yeux. Dans un jeu de données d’un sondage analysant des milliers de réponses, elle pourrait passer inaperçue pendant des mois.
Ce moment m’a fait prendre conscience d’un défi crucial pour les professionnels des études : les outils d’IA prennent des milliers de micro-décisions dans chaque projet (analyse du sentiment, classification démographique, détection de problèmes de qualité des données). Lorsque ces décisions changent subtilement, elles peuvent modifier les résultats sans aucun signe d’alerte évident.
Dans une étude, votre « quatrième luciole » pourrait être :
- Une analyse de sentiment par IA qui considère soudain « C’est correct » comme positif plutôt que neutre
- Une classification démographique qui commence à mal catégoriser les professions après une mise à jour de routine
- Une analyse de texte qui fusionne des catégories de réponses auparavant distinctes sans notification
Ces changements (appelés dérive de modèle, évolution des biais ou altération algorithmique) traduisent le même problème fondamental : les outils d’IA peuvent modifier leur comportement d’une manière qui influence les conclusions des études, tout en semblant parfaitement cohérents en apparence.
La clé, c’est de comprendre que la détection est plus importante que la prévention. Plutôt que d’essayer de figer les capacités de l’IA, nous devons mettre en place des méthodes systématiques pour repérer quand des changements se produisent et déterminer s’ils représentent une amélioration ou un problème. La validation de l’IA ressemble à la vérification des faits : il ne s’agit pas d’empêcher l’IA de faire des découvertes, mais de vérifier lesquelles nous pouvons réellement lui faire confiance.
Trois types de dérive de l’IA (et pourquoi il est essentiel de les comprendre)
Nos outils d’IA changent de comportement pour des raisons techniques prévisibles. Comprendre ces mécanismes nous aide à concevoir des protocoles de validation adaptés :
Dérive conceptuelle
- Ce qui se passe : l’IA redéfinit certaines catégories à mesure que le langage évolue.
- Impact sur les études : une analyse de sentiment fiable en 2022 peut mal classer des expressions contemporaines.
Changement dans les données d’apprentissage
- Ce qui se passe : les mises à jour du modèle intègrent de nouvelles sources de données.
- Impact sur les études : les cadres de codification changent sans avertissement explicite.
Dégradation du modèle
- Ce qui se passe : les ajustements successifs introduisent des biais cumulatifs.
- Impact sur les études : les schémas produits semblent méthodologiquement solides, mais ne le sont pas.
Toutes les évolutions de l’IA ne sont pas problématiques : certaines reflètent de réelles améliorations dans la reconnaissance des schémas. Nos cadres de validation doivent distinguer les adaptations bénéfiques des dérives préoccupantes.
Validation en pratique : quand les « quatrièmes lucioles » révèlent leur vraie nature
Dans les équipes qui mettent en œuvre la validation de l’IA, le problème de la quatrième luciole se manifeste parfois de manière inquiétante, parfois de façon utile. Dans chaque cas, une validation systématique a fait la différence entre des changements cachés qui compromettaient les résultats et des ajustements qui amélioraient la méthodologie.
Quand les « quatrièmes lucioles » posent problème
Dérive du sentiment dans les études de transport : Un suivi de satisfaction dans les transports a vu son IA commencer à coder « C’est correct » comme une réponse positive plutôt que neutre après une mise à jour. Les scores de satisfaction ont été artificiellement gonflés, et l’erreur n’a été détectée que lorsque les parties prenantes ont remis en question les résultats.
Biais dans l’inférence démographique : Un organisme d’études en politiques publiques a vu son outil d’IA mal classifier les travailleurs de l’économie à la demande après l’ajout de données d’apprentissage non vérifiées, faussant les estimations du marché du travail et influençant les recommandations politiques. L’erreur a été découverte lorsque les résultats n’ont pas correspondu aux données de référence.
Quand la validation mène à de précieuses découvertes
Évolution de la classification démographique
Lors d’un sondage national, une révision trimestrielle du modèle a révélé une augmentation du nombre de répondants classés comme « Hispaniques/Latinos » par le classificateur de texte. L’analyse a montré que la mise à jour incorporait davantage de motifs linguistiques et de combinaisons de prénoms.
Au lieu de revenir à la version précédente, l’équipe a comparé les classifications de l’IA aux auto-déclarations et aux données de l’American Community Survey. Le modèle identifiait correctement des répondants auparavant non détectés, notamment des personnes multi-ethniques et des nouveaux groupes d’immigrants, mais surestimait les résultats dans certaines régions. En conservant cette couverture élargie tout en ajoutant une question de confirmation d’auto-identification, l’équipe a amélioré la précision et limité le biais.
Évolution du langage des consommateurs
Dans un suivi de marque, l’IA a commencé à fusionner les réponses liées à la « valeur » et au « prix », auparavant codées séparément. Des tests en échantillons scindés ont révélé que les consommateurs utilisaient désormais ces termes de manière interchangeable (« Ce n’est pas à la hauteur du prix », « Bon rapport qualité-prix »). La solution a consisté à fusionner les catégories principales tout en ajoutant des sous-balises pour assurer la continuité des tendances, reflétant ainsi l’évolution du langage réel sans perdre la comparabilité historique.
Cinq composantes essentielles de la validation de l’IA
D’après l’expérience des équipes d’études ayant développé leurs propres approches de validation, voici les éléments essentiels à tout cadre complet :
- Suivi des schémas en temps réel
Méthodes de contrôle statistique permettant de signaler les écarts significatifs par rapport aux valeurs de référence et de déclencher une analyse rapide des anomalies. - Test de cohérence démographique
Évaluation systématique des décisions de l’IA à travers les classes protégées pour garantir des choix cohérents, tout en détectant les différences réelles entre groupes. - Études de validation comparatives
Analyses parallèles utilisant des méthodes traditionnelles et des méthodes fondées sur l’IA pour évaluer les avantages et les limites de chaque approche. - Documentation complète des décisions
Journalisation détaillée des choix faits par l’IA afin de permettre la révision par les pairs et la reproductibilité, même si cela accroît les exigences de planification. - Intégration de la supervision humaine
Les décisions méthodologiques critiques doivent toujours être validées par des professionnels des études, l’enjeu étant d’assurer un contrôle efficace sans créer de lourdeur administrative.
Chaque contexte d’étude nécessite un niveau de supervision adapté, équilibrant validation approfondie et efficacité opérationnelle.
Avancer collectivement en tant que communauté des études
Le problème de la quatrième luciole représente à la fois un défi et une opportunité pour notre domaine. Sans validation systématique, nous risquons deux extrêmes : être trop prudents et passer à côté du potentiel transformateur de l’IA, ou avancer trop vite et compromettre la qualité des études.
Notre profession a déjà traversé de grandes transitions méthodologiques : du papier au numérique, du téléphone fixe au mobile. Celle-ci exige la même rigueur : validation systématique, apprentissage partagé et définition collective de standards.
Voici comment développer vos capacités de validation
Étapes immédiates (prochaines 4 semaines)
- Auditez votre utilisation actuelle de l’IA et documentez chaque point de décision dans votre méthodologie.
- Établissez des mesures de référence pour les sorties de l’IA avant toute modification.
- Mettez en place un système simple pour détecter les changements inattendus de schéma.
Renforcement à moyen terme (prochain trimestre)
- Développez des protocoles de tests en échantillons scindés pour comparer IA et méthodes traditionnelles.
- Formez votre équipe à reconnaître les trois types de dérive évoqués ci-dessus.
- Intégrez les cinq composantes essentielles de la validation en fonction de la taille de vos projets.
Contribution à long terme (en continu)
- Partagez vos expériences de validation avec vos pairs, les succès comme les échecs font progresser la connaissance collective.
- Défendez la transparence de l’IA auprès de vos fournisseurs technologiques.
- Participez aux discussions professionnelles sur les meilleures pratiques.
Les équipes d’études les plus performantes considèrent la validation de l’IA comme une opportunité de développement professionnel, et non comme une contrainte. Elles renforcent leurs compétences, accumulent une expertise institutionnelle et se placent en position d’influencer le développement de l’IA plutôt que de simplement le subir.
Lorsqu’une équipe prouve la fiabilité de ses outils d’IA, elle peut exploiter pleinement la détection avancée des schémas, l’analyse multi-culturelle à grande échelle et des approches adaptatives qui répondent aux nouvelles tendances tout en maintenant la rigueur scientifique.
En conclusion
Maîtriser les protocoles de validation transforme l’IA d’une variable imprévisible en un outil fiable au service de la compréhension des opinions et comportements. Le problème de la quatrième luciole n’est pas un obstacle insurmontable, mais un défi méthodologique que l’on peut résoudre.Une fois relevé, il ouvre la voie à de véritables avancées dans le domaine des études.
Chaque luciole dans vos données doit être là pour une raison que vous pouvez vérifier et justifier.
Quelle sera votre prochaine étape vers une adoption confiante de l’IA ?
Read more
%20(1).jpg)
Analyse de texte & IA
Au-delà de la boîte noire : un cadre pour une intégration responsable de l’IA dans les études
Cet article a été initialement publié en anglais.
L’intégration de l’intelligence artificielle dans les études représente le changement méthodologique le plus important depuis la transition des questionnaires papier vers les plateformes numériques. Mais à la différence des avancées précédentes, celle-ci remet en question des fondements essentiels : le contrôle exercé par les professionnel·les des études, la transparence des méthodes et la rigueur scientifique.
Soyons clairs : l’IA n’a pas attendu notre autorisation. Elle est déjà présente dans les outils que nous utilisons pour analyser les réponses ouvertes, vérifier la qualité des données ou créer des modèles prédictifs. La question n’est plus de savoir si l’IA a sa place dans les études, mais comment nous allons encadrer son intégration avant qu’elle ne nous échappe.
De mon point de vue, une intégration réfléchie vaut mieux qu’un rejet total ou un report indéfini. Les capacités de l’IA que j’ai pu observer transforment réellement notre façon de travailler : traiter des milliers de réponses ouvertes que les budgets de codification traditionnels ne permettraient pas d’analyser, ou repérer des schémas que même des analystes expérimenté·es pourraient manquer. Il ne s’agit pas d’améliorations marginales, mais de gains d’efficacité capables de redéfinir ce qu’il est possible d’accomplir.
Ce qui m’inquiète, c’est le risque de sacrifier nos standards méthodologiques au nom de la commodité. Le véritable enjeu n’est pas de choisir entre IA et qualité, mais de garantir que nous ne compromettons pas la rigueur qui fait la valeur de notre travail. Nous pouvons concilier outils puissants et pratiques solides, mais cela ne se fera pas par hasard.
Des enjeux plus importants qu’il n’y paraît
Nous n’adoptons pas simplement de nouveaux outils : nous remettons en question les bases mêmes de la méthode scientifique.
- Que devient-elle lorsque des algorithmes guident l’analyse ?
- Comment préserver la rigueur de la relecture par les pairs lorsque les processus deviennent opaques ?
- Et comment reproduire nos résultats si nos méthodes reposent sur des systèmes propriétaires fermés ?
Les études que nous produisons orientent les décisions publiques, façonnent les stratégies d’entreprise et alimentent notre compréhension du comportement humain. Si nous privilégions la rapidité au détriment de la qualité, nous risquons de fragiliser l’un des socles de connaissance sur lesquels notre société s’appuie.
Six domaines où les études sont les plus vulnérables
1. Le problème de la boîte noire
De nombreux outils d’IA produisent des résultats impressionnants sans offrir de visibilité sur leur fonctionnement. Pour les professionnel·les des études, qui dépendent de la transparence méthodologique, c’est un signal d’alarme.
Si nous ne pouvons pas expliquer comment un résultat est généré, nous ne pouvons pas le défendre.
2. Les défis de la reproductibilité
Si je ne peux pas décrire précisément comment un résultat a été produit, comment le justifier ou le reproduire dans une étude future ?
Avec l’IA, la reproductibilité est souvent obscurcie par des processus opaques.
Dans un domaine déjà confronté à une crise de la réplication, c’est un risque sérieux.
3. Les biais et la sécurité des données
L’IA apprend à partir de données existantes, souvent marquées par des biais historiques. Sans validation régulière, nous risquons de renforcer les inégalités au lieu de les révéler.
Et lorsque l’IA traite des données à caractère personnel, les enjeux de sécurité et de conformité deviennent encore plus critiques.
4. La perte de contrôle humain
La qualité des études repose sur le jugement, le contexte et l’esprit critique.
Si des outils automatisent les décisions sans supervision humaine, nous risquons de transformer une analyse réfléchie en simple exécution mécanique.
5. La confidentialité et la conformité
Les environnements réglementés comme les secteurs public, de la santé ou universitaire exigent un contrôle strict des données personnelles.
Or, beaucoup de systèmes d’IA n’ont pas été conçus pour répondre à ces exigences, ce qui soulève des préoccupations éthiques et légales.
6. Les freins organisationnels
Même lorsque les équipes souhaitent adopter l’IA, les politiques internes sont souvent floues, et les contraintes réglementaires peuvent freiner l’expérimentation.
Il n’est pas rare qu’un service teste des outils d’IA pendant qu’un autre en est empêché, ce qui crée confusion et lenteur.
Une adoption fragmentée, mais inévitable
L’un des défis majeurs de cette transition est l’adoption inégale, même au sein d’une même organisation. Certaines équipes expérimentent l’IA discrètement, tandis que d’autres imposent des restrictions strictes. Cette incohérence crée de la méfiance et freine les progrès.
Plutôt qu’une transformation globale, nous observons une adoption progressive, menée par des équipes pilotes. Cette approche ascendante permet de tester les outils d’IA dans des contextes spécifiques et de bâtir la confiance institutionnelle au fil du temps.
Ce que recherchent les professionnel·les des études
Quand je parle avec mes pairs, leurs attentes sont claires. Ils ne veulent pas d’une IA « tout-en-un », mais des outils qui :
- Facilitent le codage des réponses ouvertes à grande échelle tout en maintenant la cohérence et le contrôle humain.
- Aident à interpréter les réponses et à suggérer des relances pertinentes lors de la conception ou de l’analyse des enquêtes.
- Évaluent la qualité des données en attribuant des scores de validité ou de risque, sans supprimer automatiquement les réponses.
- Intègrent des boucles de rétroaction où l’humain peut corriger, affiner et faire évoluer les résultats de l’IA au fil du temps.
Ces demandes reflètent une compréhension mature du rôle de l’IA : non pas remplacer le jugement humain, mais étendre les capacités des équipes d’études tout en conservant la maîtrise du processus.
Un cadre pour une intégration responsable : IA + IH
Nous avons besoin de standards, pas de slogans. Voici le cadre que je propose :
1. Preuve de performance
Les plateformes doivent fournir des rapports de validation indiquant la fiabilité inter-codeurs, les performances par sous-groupes et les taux d’erreur.
Inutile d’exiger l’accès aux données d’entraînement ; il faut surtout des preuves que le système fonctionne dans des contextes comparables au vôtre.
2. Contrôle humain intégré
Les suggestions générées par l’IA doivent rester modifiables et facultatives.
Aucune automatisation « boîte noire » : les équipes doivent garder une visibilité complète sur les entrées, les sorties et la mise en œuvre.
3. Outils de traçabilité et de reproductibilité
Chaque action doit être enregistrée, horodatée et documentée.
Même si les modèles de langage ne garantissent pas une répétabilité parfaite, une documentation complète des paramètres, des invites et des résultats est essentielle.
4. Surveillance continue des biais
Les plateformes doivent permettre des vérifications régulières des biais sur les principaux sous-groupes.
Lorsque les modèles sont utilisés en dehors de leur champ validé, les utilisateurs doivent en être avertis et redoubler de vigilance.
Avant d’adopter une solution : les bonnes questions à poser
Lorsque vous évaluez un outil d’IA appliqué aux études, interrogez vos fournisseurs sur :
- Comment validez-vous les performances selon les différents groupes démographiques ?
- Que se passe-t-il si le modèle est appliqué à un nouveau type de données ?
- Quel niveau de contrôle ai-je sur l’analyse finale ?
- Fournissez-vous une documentation complète pour la relecture ou la conformité ?
- À quoi ressemble votre processus de formation et d’intégration ?
Une adoption réaliste et progressive
L’intégration de l’IA ne sera pas immédiate. Les premières implémentations prendront du temps : protocoles de validation, formation, supervision. Mais une fois l’outil maîtrisé, les gains sont réels : codification plus rapide, support multilingue et économies mesurables. L’important est d’avancer avec réalisme et rigueur, sans se fier aveuglément aux promesses d’efficacité.
Considérations réglementaires et professionnelles
Pour les organisations soumises à des règles strictes (institutions publiques, santé, universités), les meilleures plateformes collaborent désormais avec les comités d’éthique et les autorités de protection des données afin de proposer des protocoles conformes aux réglementations (RGPD, HIPAA, etc.).
Nos associations professionnelles devraient, elles aussi, définir des standards sectoriels pour la validation de l’IA dans les études : exigences de documentation, tests de biais et supervision humaine. Il nous faut des lignes directrices claires sur la divulgation de l’usage de l’IA dans les publications et sur la responsabilité professionnelle en cas d’automatisation.
S’engager intelligemment, pas adopter aveuglément
Je ne plaide pas pour une adoption sans discernement, mais pour une implication réfléchie. Les capacités de l’IA évoluent, que nous le voulions ou non. La question n’est pas de savoir si notre domaine va changer, mais si nous allons contribuer à ce changement ou le subir.
L’opportunité est immense : nous pouvons analyser des réponses ouvertes à des échelles auparavant inaccessibles, détecter des tendances subtiles en quelques heures, et accélérer les délais de livraison sans sacrifier la qualité. Mais rien de cela ne se produit automatiquement. Cela exige de rester actif, critique et engagé dans la construction d’outils au service de la qualité des études.
Nous avons plus d’influence que nous ne le pensons. Les entreprises qui développent ces outils sont à l’écoute de nos besoins, mais uniquement si nous savons les exprimer avec clarté, réalisme et cohérence. Si nous abordons l’intégration de l’IA avec discernement, nous pouvons contribuer à créer des outils véritablement adaptés aux exigences des études, plutôt que d’avoir à nous adapter aux limites technologiques.
Ce que cela signifie pour notre secteur
L’avenir des études repose sur notre volonté de collaborer de manière constructive avec ces technologies.
Nous ne devons être ni des adopteurs précipités ni des opposants systématiques, mais des acteurs engagés capables d’orienter le développement de l’IA au service de la rigueur scientifique.
Cela implique de :
- Participer à des études de validation et partager nos expériences avec les outils d’IA.
- Collaborer avec les concepteurs pour créer des systèmes alignés sur nos standards professionnels.
- Former la nouvelle génération à comprendre les capacités et les limites de l’IA tout en tirant parti de ses véritables avantages.
- Préserver la rigueur méthodologique qui a toujours défini la qualité des études, même en adoptant de nouvelles approches.
Les outils d’IA les plus efficaces ne remplaceront pas les professionnel·les des études : ils les rendront plus performants.
Mais ce résultat n’est pas garanti. Il exige que nous restions impliqués, que nous demandions mieux et que nous refusions les solutions qui nous obligent à choisir entre efficacité et rigueur.
Un moment décisif pour les études. Nous sommes à un tournant. Nous pouvons laisser l’IA s’imposer à notre domaine ou choisir d’en orienter le développement. Je suis convaincu que nous avons à la fois l’opportunité et la responsabilité d’opter pour la deuxième voie.
Michael W. Link, PhD, est une référence dans le domaine des méthodologies d’enquêtes et de l’intégration de l’IA. Ses travaux se concentrent sur la préservation de l’excellence scientifique tout en favorisant l’innovation technologique.
Read more

Les dernières tendances en études de marché
Analyse de texte & IA
Vos questions de sondage ne vont-elles pas jusqu’au fond des choses ? L’Approfondissement par l’IA pourrait bien vous surprendre
Si vous avez déjà conçu des enquêtes, vous avez sûrement vécu ça : vous posez une question ouverte en espérant une réponse riche et nuancée... et vous obtenez... “C’était correct.” Pas très exploitable, n’est-ce pas?
Vous savez que le répondant(e) pourrait en dire davantage, mais le questionnaire poursuit son cours. Aucune relance, aucun approfondissement, aucun véritable éclairage. C’est là que l’Approfondissement par l’IA fait vraiment la différence. Ce n’est pas un mot à la mode : c’est un outil concret qui vous aide à poser de meilleures questions pour obtenir de meilleures réponses.
Qu’est-ce que l’Approfondissement par l’IA ?
Concrètement, cela signifie que votre enquête ne s’arrête pas à la première réponse. Le système analyse ce que dit le·la répondant·e et, si la réponse paraît vague ou incomplète, il pose une question de suivi pertinente, en temps réel.
Par exemple, si la réponse est : « Le produit était déroutant », l’IA pourrait demander : « Pouvez-vous nous préciser quelle partie était la plus déroutante ? »
Cette deuxième question est souvent celle qui fait émerger l’insight vraiment utile.
Pourquoi cela fait-il sens aujourd’hui ?
Soyons honnêtes : les gens ne fournissent pas toujours des réponses approfondies. Fatigue, précipitation, incertitude sur le niveau de détail attendu… sans encouragement subtil, les données restent superficielles.
L’Approfondissement par l’IA vous permet de :
- Clarifier les réponses floues avant la fin du sondage
- Encourager les répondant·es à développer leur réflexion
- Capturer des informations émotionnelles ou motivantes
- Réduire les relances ultérieures
- Gagner du temps lors de l’analyse, avec des données déjà plus riches
C’est l’occasion de redonner une seconde chance aux réponses ouvertes — souvent, il y a plus à entendre lorsqu’on leur demande.
Un outil flexible, et c’est une bonne chose
L’un des principaux avantages ? Vous contrôlez le comportement de l’IA : rien n’est laissé au hasard.
Par exemple, vous pouvez :
- Informer l’IA sur l’objectif de l’enquête (sentiment, motivations, besoins non satisfaits)
- Activer une assistance subtile pour orienter ou reformuler le cas échéant
- Ne pas approfondir certaines réponses courtes ou détachées, si cela perturbe le flux
- Définir un nombre maximal de relances (souvent une ou deux suffisent), pour préserver la fluidité
En somme, ce n’est pas abandonner le contrôle, mais affiner la façon de demander plus — selon ce qui fonctionne avec votre audience.
L’humain dans cette technologie
Petit rappel : « IA » ne signifie pas « robotique ».
Les relances doivent paraître naturelles, cohérentes avec le ton de l’enquête, et non pas comme un chatbot qui tente maladroitement de créer un lien. Une petite notice comme « Vous pourriez recevoir une question de suivi en fonction de votre réponse » peut renforcer la transparence et la confiance.
Et n’oubliez jamais le respect de la vie privée, surtout pour des sujets sensibles : anonymat et ton respectueux sont essentiels.
Pas sûr·e par où commencer ?
Pas besoin de l’appliquer à tout le sondage d’emblée. Commencez par une ou deux questions clés où le détail compte vraiment.
Évaluez la réceptivité, les abandons, la richesse des réponses. Vous verrez rapidement la valeur ajoutée.
Avec le temps, peaufinez l’approche et explorez son usage dans d’autres contextes (feedback employés, image de marque, etc.).
À venir : des avancées prometteuses
L’Approfondissement par l’IA est encore jeune, mais il transforme déjà la façon de recueillir des retours textuels. Plus besoin de se contenter de réponses d’un mot.
À l’avenir, on peut imaginer des relances plus sensibles à l’émotion, une meilleure gestion multilingue, et une connexion plus fluide avec d’autres outils d’études.
Pour l’instant ? C’est un moyen simple et efficace d’améliorer vos enquêtes, sans ajouter de longueur ni de complexité.
Conclusion
De meilleures données commencent par de meilleures questions. Mais parfois, une seule question ne suffit pas. C’est là que l’Approfondissement par l’IA devient utile. Ce n’est pas remplacer les professionnel·les des études, mais les aider à faire dire ce que les gens ont vraiment à dire.
Et quand on obtient des insights utiles ? Tout le monde y gagne.
Curieux·se de tester l’Approfondissement par l’IA dans votre workflow ? Si vous êtes client·e : contactez votre gestionnaire de compte pour découvrir les options et bonnes pratiques. Si vous découvrez Voxco : Réservez une démo maintenant.
Read more

Les dernières tendances en études de marché
Why AI is Your Secret Weapon for a Thriving Market Research Career
I’ve spent over two decades building technology companies. Before that I started my career in research and so building technology for researchers has brought me full circle. I’ve seen firsthand how big tech shifts can cause fear but also open new doors. AI’s impact on market research from 2023 to 2025 is profound: it’s changing workflows, roles, and outcomes. But here’s the truth—AI isn’t here to replace you. It’s here to empower you. Think of it as an experienced instructor standing next to you as you work and pointing the finger at what is important and better ways to do things.
I’m the CEO of Voxco, a leader in survey and text analytics technology, working at the frontline where AI meets market research. This isn’t speculation—it’s real change unfolding in companies I work with daily. I’m sharing what I’ve learned to help you thrive in this new landscape.
The Collapse of Traditional Roles Is Happening — and It’s a Good Thing
From survey designers and data analysts to insight strategists, AI tools are combining many tasks into one streamlined process. This shift means:
- Surveys that once took days to program are made efficiently with AI, reducing human hours.
- AI chatbots can now conduct interviews and focus groups, cutting down on the need for human moderators.
- Data analysis that required weeks is now done in minutes with natural language processing and automated significance testing.
- Once feared for their complexity and cost, open-ended questions now flourish—empowered by AI’s ability to summarize, categorize, and scale understanding.
- Automated reports with narrative insights and recommendations come out in seconds, not days.
One perspective is that this consolidation is a bad thing for workers, another is that this is a blurring of roles that brings more productivity to our field. Some people will come out of this with vastly more value to their customers and the market. Those are the people that learn to work through these blurred lines of roles. Shifting your focus from lower level to higher-value analysis and strategy could make you even more valuable to your organization or team.

The Current Market Shift and What That Means for You
We’re already seeing a fundamental shift in both the fabric of how we conduct research and the speed at which we analyze data. Take a look behind the curtain:
- Screen Engine uses AI to analyze moviegoer feedback in near real-time, enabling studios to tweak marketing and editing quickly before release—saving money and improving results.
- Ascribe AI automatically generates rich reports from open-ended survey data, combining qualitative and quantitative themes in seconds.
- A Wisconsin School of Business study found generative AI can deliver qualitative insights comparable to seasoned human analysts, speeding up deep thematic analysis.
But the shift isn’t just at the study level; both teams and organizations are seeing large scale change:
- AI reduces routine survey and data work by over 90% in some cases.
- According to University of Leeds research, AI could improve business efficiency and cut costs by 30% by 2035 in data-heavy roles.
- McKinsey reports firms using AI analytics have 20% higher productivity and innovate 30% faster.
If you’re feeling a seismic change reverberating beneath your feet, take heart. Although traditional junior roles like survey programmers and entry-level analysts are shrinking, there is an opportunity here to own the future if you are willing to evolve. Being of value and rising to the challenge won’t rest on manual data crunching. If you’ve already shifted focus to AI oversight, interpretation, and ethical insight generation, you’ve won 80% of this change already.
Here’s Your Market Research Career Roadmap in the AI Era
Given these changes, it’s smart to lay out a plan for how you might create extraordinary momentum in your marketability in a matter of years. If you can see the terrain changing, why not build a perfectly adapted vehicle to take you toward the horizon?
Step 1: Master AI Tools & Interpretation
This is your time to get acquainted with the landscape and familiarize yourself with the newly available tools. Getting your tools to a point of being ready for projects, means using them right away:
- Starting from scratch? That’s fine. Start using 2-3 LLMs (ChatGPT, Claude, etc) as a thought partner in your research.
- The more you teach the models about who you are, what you do and refine the rules of working with you, the more you will get out of them. It is like a friendship in a way; being authentic and open leads to better results.
- Now you are ready to use the tools in your projects for AI output quality and spotting errors.
- Try some of the coding open-ended response analysis and sentiment detection tools.
- The most important part of Step 1 is to just get started. Experiment. Failures lead to learning.
Step 2: Become an AI-Augmented Researcher, Blurring the Lines of Traditional Roles
After Step 1, you’re in the trenches and you know what’s available and how it performs. You’re becoming a master at coaxing insight out of AI. As you gain momentum, you might:
- Guide AI in custom insight generation.
- Develop expertise in integrating AI findings with business context.
- Hone storytelling skills to translate data into strategy.

Step 3: Lead AI-Driven Insight Strategy, Changing Your Whole Business
This is your time to mentor others and to start to lead out the discussion of where market research can and should go next with AI-augmented research. Asking questions about what limitations are removed by your new efficiency will lead to whole new strategies. Strategic moves might be to:
- Change how you work with customers on projects - how much more data can be provided for projects such as product launches, pricing analysis, sentiment analysis at the same budget they have had before? What better decisions will your customer make and what better outcomes will they have with this added analysis you can provide?
- How can you measure a ‘before’ state of traditional market research, and this changed model you have built? How can you use that to win new customers or expand work in the ones you already have?
- Can you build a new flexible model for how work gets done in your firm? Shape ethical guidelines and quality standards for AI research use.
- Mentor junior analysts to adopt AI fluency and this new model.
Step 4+: Innovate & Influence
This is what you’ve been building toward - ones where your thought leadership is valued because you’ve been in the trenches, know the tools and can see how AI-augmented research functions across platforms. You might:
- Pioneer new AI-driven research methods and platforms.
- Advise leadership on AI’s impact on market and customer understanding.
- Build cross-functional teams that leverage AI for continuous decision-making.
You’re In the Driver’s Seat if You Can Adapt
Yes, some roles are already diminishing to partial roles, but getting current with new tools and skills will accelerate you to the top of the list for newly created roles that will inevitably follow. Imagine a world where analysts become insight orchestrators, survey programmers become research program designers and all research professionals provide far more insights than ever before.
Goldman Sachs estimates 18% of jobs globally could be automated by AI—but many market research roles are evolving, not vanishing. It's time for reimagining and adaptation.
The Big Picture & Final Thoughts - Think with Abundance
AI is pushing down the cost of research dramatically and speeding up insight cycles by factors of 10 or more. This is deflationary—it means research becomes cheaper and more accessible, benefiting businesses and consumers alike. Stop imagining a world with the same amount of data for a lower price and start imagining a world with far more data within shorter time periods - this thinking with abundance will lead to better outcomes for your customers’ outcomes, your team’s success and the market’s growth. At the same time, faster, richer insights drive innovation and economic growth. Per Brad Gerstner, AI-driven productivity gains are expected to add $10 trillion of global productivity per year over the next several years, which is an almost unfathomable change to our world and is almost completely driven inside knowledge work - like Market Research.
The AI revolution in market research is real, but it’s not a threat if you are game to adapt—it’s the biggest opportunity of your career. Those who harness AI’s power will accelerate their careers, deliver better insights, and help their companies innovate faster. Be the researcher who partners with AI, not the one replaced by it - that is only the beginning, the real win is to be part of the elite team of researchers that drives our market to a place of abundance.
And remember, it’s not about owning the machine; it’s about knowing how it works. When word processers came along, just like AI today, they were there to stay and get only better with time. Word processors did not replace writers—they amplified them. In the same way, AI doesn’t replace thinking; it rewards those who think clearly and know how to ask the right questions.
If you want to dive deeper, I’m always open to sharing what I’ve seen at Voxco and across the industry. Together, we can turn AI from a fear factor into a career accelerator. Click here to connect with me on LinkedIn.
Read more

Analyse de texte & IA
Comment choisir la bonne solution
Accélérez vos insights : Ascribe à l’honneur dans Quirk’s Innovative Products & Services
Les réponses ouvertes offrent de la richesse, mais les transformer en insights exploitables reste un défi. L’article de Quirk’s intitulé “Accelerate insights! Simplify analytics with Ascribe” met en lumière la façon dont les solutions d’Ascribe, basées sur l’IA, facilitent cette tâche. Qu’il s’agisse de coder des réponses à des sondages ou d’analyser des commentaires clients issus de sites web ou des réseaux sociaux, les outils d’Ascribe — Theme Extractor, Ask Ascribe et Visualizations — permettent une analyse textuelle fiable, rapide, et avec un minimum d’intervention humaine, jusqu’à 90 % plus rapide. L’utilisateur garde le contrôle sur le niveau d’automatisation, choisit quand utiliser l’IA générative, et peut ajuster les résultats.
Des innovations conçues pour accélérer l’analyse des réponses ouvertes
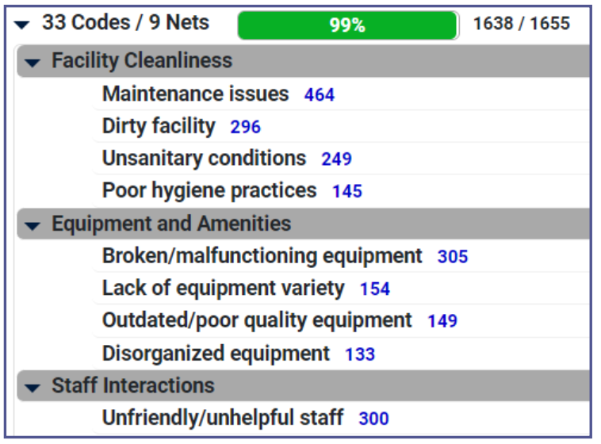
Theme Extractor : rapidité et précision inégalées
Au cœur de l’innovation Ascribe se trouve Theme Extractor, un moteur d’analyse textuelle propriétaire basé sur l’IA et le traitement du langage naturel (NLP). Il identifie instantanément les thèmes les plus importants dans les réponses ouvertes — qu’il s’agisse de sujets, de sentiments ou d’émotions. Il génère un codebook clair, structuré autour de thématiques et de sous-thématiques hiérarchisées. Ensuite, il code automatiquement plus de 95 % des réponses avec une précision remarquable.
Theme Extractor peut également traiter des études multilingues : il suffit de sélectionner la langue souhaitée pour les résultats. Aucune taxonomie, règle ou jeu d’exemples n’est requis. Et les codebooks peuvent être réutilisés pour de futures études.
Ask Ascribe : interrogez vos données, comme en conversation
Ask Ascribe permet de poser des questions directement à un jeu de données : l’outil génère instantanément des réponses sous forme d’insights, de résumés ou de rapports. Qu’il s’agisse d’identifier des thèmes clés, d’analyser des émotions ou de détecter des axes d’amélioration, Ask Ascribe rend l’analyse aussi simple qu’un échange.

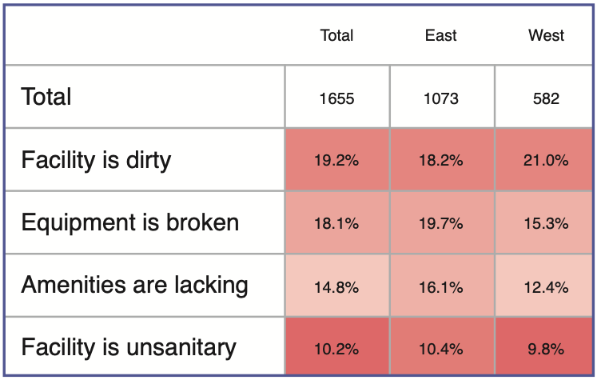
Visualisations Ascribe : des insights clairs en un clin d’œil
Ascribe ne se contente pas d’analyser vos données : il les transforme en visualisations percutantes. Graphiques dynamiques et infographies permettent d’observer d’un coup d’œil les tendances, émotions et opinions dominantes. Il est possible d’appliquer des filtres ou d’explorer les verbatims pour aller plus loin.
Une technologie pensée pour les professionnel·les d’aujourd’hui
Avec plus de 25 ans d’expérience, Ascribe continue d’innover pour proposer des solutions d’analyse textuelle adaptées aux exigences actuelles. Pour les professionnel·les des études, du CX ou les analystes, ses outils dopés à l’IA permettent de simplifier les flux de travail, gagner en productivité, accélérer les insights et améliorer la prise de décision.
Prêt·e à simplifier l’analyse de vos commentaires ouverts ?
Les innovations IA d’Ascribe sont intégrées dans Ascribe Coder et CX Inspector. Vous voulez les tester avec vos propres données ? Réservez une démo gratuite dès maintenant.

À lire sur le site de Quirk’s (Veuillez noter que l’article est rédigé en anglais) : Accelerate insights! Simplify analytics with Ascribe
Read more