



Written by
Michael W. Link, PhD
Picture this: It's 2 AM, and somewhere in the basement of a survey research firm, a single programmer is hunched over three monitors, empty energy drink cans scattered around like digital tumbleweeds. The client needs the impossible by morning: custom quota logic that shouldn't exist, a data export format that defies reason, and a survey flow that would make a PhD in logic weep.
But somehow, Fariborz makes it happen.
You know Fariborz, don't you? Perhaps at your company, he goes by Suresh, Bill, Larry, or Nate. Every survey organization has its "guru in the basement," that brilliant, slightly mysterious programmer who could make CATI systems sing opera and web platforms perform circus tricks. Our secret weapon, these programmers could turn a client's "absolutely impossible" into "done by Monday, with documentation."
For decades, this culture of homegrown ingenuity was our competitive edge. It carried us through every seismic shift in our industry: from paper questionnaires to computer-assisted telephone interviewing (CATI), from CATI to mixed-mode approaches, from mixed-mode to the digital revolution. And it worked beautifully because survey transitions unfolded predictably. The underlying mathematics remained constant, the logic was deterministic as clockwork, and a single clever programmer could keep an entire operation running smoothly for years with only occasional maintenance.
When clients needed customization, the requirements were reasonably clear: skip patterns that made sense, custom exports in familiar formats, quota logic that behaved rationally. The genius sat just down the hall, so fixes were fast, affordable, and almost always worked precisely as intended. It felt like having a Swiss Army knife that could solve any problem.
But then came AI. And suddenly, the very model that made us nimble may now be putting us at extraordinary risk.
The Day Fariborz Met His Match
AI isn't just another software upgrade or another tool in our familiar toolkit. It's a fundamentally different creature that plays by entirely different rules.
Unlike the deterministic systems we’ve grown comfortable with, AI, particularly Generative AI, is inherently non-deterministic. Feed it the same input on Tuesday that you fed it on Monday, and you might get a different output. Not because something is broken, but because that's how these systems work. Designed to mimic human "thinking," which, as we know, is not always predictable.
Moreover, AI systems demand constant care and feeding in ways that traditional software never did. Models “drift” as language evolves, populations shift, or new versions are released. What worked well for your automated open-end question coding in January might be subtly failing by June, and you won't necessarily know unless you're actively monitoring it.
Perhaps most unsettling of all, AI often can't explain its own decisions. Without sophisticated tools for interpretability, you may never understand why your model classified a response one way rather than another. As I've argued extensively in Beyond the Black Box, AI systems must be transparent, auditable, and explainable, not just for ethical reasons, but for practical ones.
As I warned in The Fourth Firefly Problem, if we're not vigilant, we can completely lose sight of minority voices and rare but critical cases. The terrifying part? We might never even realize what we've lost.
The bottom line is stark: you cannot "set and forget" an AI system the way you could with traditional survey software. And this time, there is no Fariborz working magic in the background. These systems require continuous monitoring, regular retraining, and ongoing governance, or they will quietly fail you in ways you won't discover until it's far too late.
Why AI Fails Quietly
I've seen what happens when governance isn't in place, and it should keep any research director awake at night.
One organization I spoke with built a DIY text classifier to code open-ended responses. For months, it worked beautifully: faster than human coders, more consistent, cheaper. Leadership was thrilled.
After six months, during a routine audit, they discovered the system had gradually stopped classifying Spanish-language responses correctly. No alerts. No dashboard warnings. No red flags. More than 400 Hispanic respondents had been systematically misclassified, their voices distorted in the data.
This silent failure had been happening for months before anyone noticed. That's the insidious danger of ungoverned AI. Systems don't typically crash dramatically. Instead, they drift away from accuracy, taking your data integrity with them. Model drift degrades outputs without warning. Bias creeps in slowly, overlooking minority groups or amplifying stereotypes. The talent burden alone is staggering, you need data scientists, ML engineers, and compliance specialists, not just a few clever programmers.
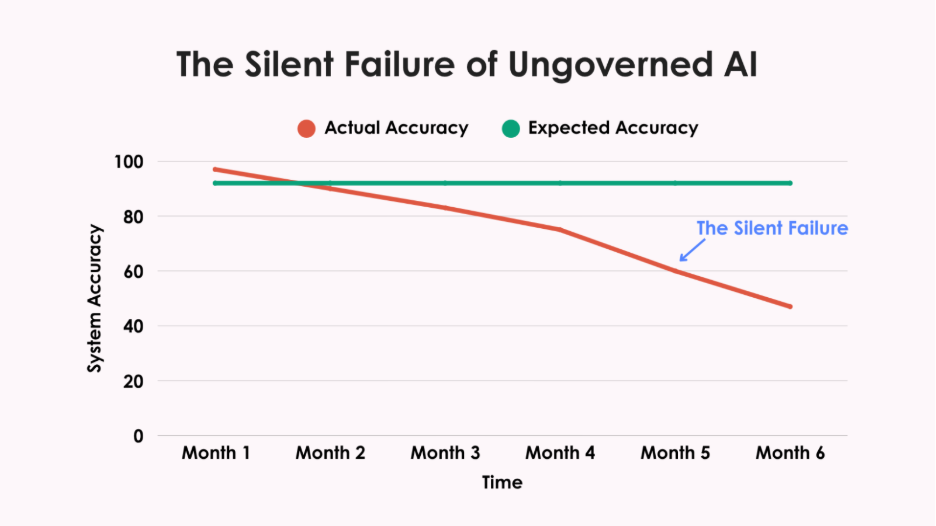
Then there's regulatory exposure. GDPR and HIPAA demand clear documentation of how your models work and protect data. NIST's framework may be “voluntary,” but try explaining that to clients when your AI system fails an audit. Can your basement genius provide that while keeping the lights on?
The lone genius can't carry this weight anymore. Expecting them to is both unfair and dangerous.
Where DIY Still Makes Sense
Don't panic. DIY isn't completely dead. It still works perfectly for:
- Pilots & experiments where you're learning and testing
- Niche internal tools solving particular workflow problems
- Prototypes that help you figure out what's worth real investment
But once your homegrown tool becomes client-facing, compliance-critical, or mission-essential? The stakes change completely.
Why Strategic Partnerships Matter
This is why teaming has become crucial. There are companies whose entire business revolves around survey platform development, and today, that means keeping up with AI's relentless pace.
These organizations maintain dedicated teams focused on tracking model developments, building MLOps pipelines, monitoring for drift and bias, and staying current on rapidly changing privacy regulations. Most importantly, their business model depends on doing this well continuously.
When you partner with platform specialists, your team can focus on what truly differentiates you: understanding respondents, serving clients, and advancing survey science.
Practical Governance Without Losing Your Mind
Even when you partner with AI specialists, governance remains your responsibility. The good news? Effective AI governance doesn't require a PhD in machine learning or a massive budget.
Here's your practical starter kit:
- Benchmark performance: Set a baseline accuracy rate at launch and then recheck it quarterly to ensure ongoing consistency. No exceptions.
- Flag the outliers: Create processes for human review of unusual outputs. These edge cases often reveal problems before they spread.
- Audit for bias: Test cases across key demographic subgroups. If outputs vary inappropriately, you'll catch it early.
- Document everything: How it was trained, when it was updated, and what metrics you monitor. This is no longer optional; it's now required.
The Three-Question Test
Before you build any new AI tool, run this simple test. If you can't answer all three confidently, stop building:
1. Who owns this model after launch?
Name the specific people responsible for monitoring, retraining, and validation. "The team" isn't an answer.
2. How will you know when it fails?
AI failures are silent. What alerts or dashboards will catch problems before clients see them?
3. What happens at 10x scale?
Can your infrastructure, staff, and governance handle ten times the workload without breaking?
Can't answer these with specifics? That's your signal to either strengthen your governance or partner with someone built for this complexity.

Bottom Line
The basement genius era isn't coming back, at least not for AI. We need to build research ecosystems where human experts and AI work together safely, transparently, and at scale.
Fariborz was our secret weapon for decades. But who's watching the models now? Are you confident they'll still be accurate in six months?
The most significant risk isn't building too slowly. It's building without guardrails, deploying systems that work beautifully until they silently fail, taking your data integrity down with them.
The models need their own watchers. Can you afford proper AI governance? Better question: can you afford not to have it?
%20(1200%20x%20924%20px).png)


